Common RBA Use Cases
RBA provides the ability to automate, create, define, document, orchestrate, manage, and report on workflows that support orderly scheduled or event-driven execution of system and network processes. RBA processes transcend IT disciplinary boundaries and establish interactivity across diverse infrastructure elements (including applications, databases, services, and hardware) to apply IT best business practices across an enterprise. RBA processes also provide tighter software integration, improve IT service levels, and automate resource provisioning through event- and process-driven workflows.
RBA significantly enhances efficiency levels, particularly for routine or regularly repeated business operations, and permits easy automation of manual procedures. Specific alerts, events, and incidents may be captured, monitored, and examined—by man, machine, or both—to identify better methods for managing and maintaining workflows. Furthermore, RBA integrates business components tightly and acts as an industrial-strength adhesive to bind large heterogeneous IT environments. All in all, RBA helps businesses handle the enormous and complex administrative challenge that goes by seemingly innocuous names such as "IT operations," "IT Service Support," "IT Service Delivery," and "ICT Infrastructure Management" (ICT stands for Information and Communication Technology), to pick up key elements from the ITIL v3 Framework.
Certain RBA solutions can even execute multiple aspects of IT procedures in parallel while simultaneously synchronizing intercommunication between or among them, and can escalate selected events for administrator attention according to specific triggers, event severity levels, threshold values, or even for particular combinations of events. All RBA solutions perpetually measure, monitor, and maintain enterprise-wide performance levels to help ensure that SLAs are met. Another competitive advantage of certain RBA solutions is their ability to analyze workflow procedures to reduce end-to-end process lag. Such lag negatively impacts business and can reduce efficiency and economy.
Complete examination of workflow procedures illuminates a plethora of wasteful wait-states that can result from
- Running tasks on hold, pending acknowledgement of some kind
- Running tasks on hold, awaiting validation
- Running tasks on hold, awaiting further action (approve/disapprove/modify)
The RBA bottom line is that this technology empowers frontline operators (such as Tier-1 support staff or frontline Help desk professionals) with improved access to and control over diagnostic and remediation procedures. This enables personnel to solve more complex issues that might otherwise involve more seasoned upper-level Tier-2 or Tier-3 staffers. Accordingly, RBA enables enterprise IT to increase its operational efficiencies by reducing overall alert volumes all the way up the escalation ladder, especially by pushing remediation and resolution tools and techniques into the lower rungs (or tiers, if you prefer) of such organizations. In fact, the very kinds of personnel savings that such capability can support help to justify the cost of investing in RBA.
Bear in mind, there are generic process solution providers—a one-size-fits-all paradigm that provides closed loop management—and specific process providers that leverage existing tools from other vendors. Let's now change gears to explore and examine generically described example usage case scenarios to better illustrate how RBA may best be deployed and used in an enterprise context.
Loop management is a broad subject encompassing design, configuration, performance tuning, continuous monitoring, fault diagnosis, routine maintenance, and change management (among other considerable aspects of IT management). A closed loop management scenario involves a continuous flow of pertinent information from monitoring agents to management personnel. It also includes the automatic invocation of IT-specific processes that ready the IT environment for planned and unplanned changes.
Case 1: Event Resolution
As described in Chapter 2, RBA platforms capture ad hoc maintenance procedures and management tasks that typically leverage cumulative experience, collective wisdom, and tribal knowledge. Alert, event, and incident handling normally characterize labor-intensive, timeconsuming firefighting tasks that burden IT operations and consume much of its time, effort, and budget. Traditionally, monitoring system applications, systems, and network infrastructure requires deployment of individual monitoring agents, which incur additional overhead for installation and upkeep tasks. Organizations can leverage RBA platforms to utilize agentless approaches, automation, and application programming interfaces (APIs) to execute corrective or executive actions when alerts, incidents, and events occur.
Many organizations find that up to half of all incidents are escalated to Tier-3 systems and network administrators after initial handling by frontline operators. Excessive or frequent escalations can prove costly in terms of money and time spent during the resolution phase, which impacts the entire IT organization's scope of operation. In such instances, even a marginal reduction in incident volume can free up at least some IT support personnel to focus on more strategic and proactive operations tasks. A large-scale company may process millions of transactions on computer systems exercising thousands of different tasks. Thus, when problems or routine maintenance tasks arise, they can levy a massive drain on IT resources unless tools and techniques are available to automate what can be automated and to quickly identify and resolve truly critical incidents or issues.
Without workflow automation, existing incident-handling procedures incur operational penalties that include unplanned downtime and development cycles. With a proper workflow automation platform, all organizational elements are documented, detailed, and defined in a centralized run book repository that better empowers Network Operations Center (NOC) support staff to identify relevant systems, parts, and problems. RBA's event and incident resolution mechanisms automate common, repeated tasks and processes associated with diagnosis and resolution strategies. This setup eliminates alert floods, reduces escalated event volumes, and empowers frontline IT operators to do more on their own recognizance.
RBA incorporates tribal knowledge skills and techniques utilized in the typical three-part diagnostics, triage, and repair processes so beloved of Tier-3 experts. This describes a common approach to problem solving for escalated problems or trouble tickets, wherein network experts begin by running diagnostics; examining relevant log files or alert and alarm text to look for causes and to determine the scope of systems and links affected (diagnostics); and implementing immediate workarounds or temporary fixes to address the most chronic symptoms (triage), ultimately resulting in permanent changes, fixes, or upgrades to address causes and complaints fully (repair). When this kind of skill and knowledge gets codified into RBA processes, Tier-1 frontline personnel become capable of performing routines and executing tasks that were once the exclusive province of escalated incident resolution. RBA tools can automatically diagnose and remedy a broad range of incidents, not only drastically shortening incident resolution times but also resulting in far fewer escalations overall. Problem identification or diagnosis is the first part of the resolution course. A descriptive example appears in the following passage.
The Problem
High-alert volumes flood the NOC, prohibiting Tier-1 support personnel from resolving incidents in a timely manner and resulting in more escalations than are reasonably manageable. Tier-3 administration becomes over-involved with routine clean-up phases that follow from "casual spills" and "routine messes" within the IT environment—issues mostly of minimal importance and generally of low criticality. A single IT issue can potentially trigger hundreds of alerts spread across multiple network monitors on numerous elements within the organizational network.
The Solution
RBA provides visually guided workflows, controlled access to secured systems, automatic resolution of repetitive tasks or recurring incidents, and detailed audit trails integrated with ticketing. A successful ITIL incident management solution is not solely comprised of monitoring software, which is insufficient by itself as an enterprise-wide solution. Monitoring complex IT applications and infrastructure can and does mitigate potential incidents and alerts but only a comprehensive and complete RBA platform provides necessary follow-up triage, diagnosis, and repair procedures, as well as automatic process and post-mortem reporting.
The Process
End-to-end incident management begins with event monitoring. The receipt of some action or activity such as a blade server outage triggers an automation process. Event monitoring filters notifications and triggers applicable policies when and where necessary (a reboot for an Exchange server whose primary processes become "hung," for example). The system may respond by taking corrective action through automatic Help desk ticketing, and may also shuttle information to other relevant system management tools and consoles.
In the real world, event and incident alerts have become an exercise in avalanche counter-tactics. A single isolated incident can potentially trigger several administrative monitors and reporting tools that might also lean on other applications for a responsive, proactive resolution. This avalanche of alerts overwhelms IT administrators for what is essentially an isolated issue.
Event Detection/Notification
Incidents are detected by proactive monitoring tools, which observe system and network conditions for escalated events—including those not yet defined or encountered. Event correlation software reduces alert volumes to prevent flooding. It focuses on a specific single root cause and directs attention toward the area of interest through a redundancy eliminating process called data deduplication. Automated ticket generation escalates trouble ticket items to the appropriate responsible groups and tracks status for the lifetime of the problem.
Problem Identification
Self-healing systems incorporate software tools to diagnose and repair problems through a series of manual, guided steps or with automated data gathering analysis tools. Such a system achieves problem identification by offering preconfigured templates that address individual application complexities across diverse platforms. These interfaces supply all the application expertise that is necessary in a complicated realm of service-oriented architectures (SOAs), without requiring frontline staff to learn and master all the underlying details.
Numerous preconfigured resolution workflows exist to address a variety of topics. They check server status and network health, identify application connectivity and configuration issues, and correct and validate settings or restart stalled devices.
Diagnosis and Problem-Solving
RBA triggers a repair workflow either through initiating a self-heal mode or manual intervention by an operator using a visually guided diagnostic routine. This facilitates root cause diagnosis and documentation of a resolution workflow, allowing organizations to create their own "expansion packs."
RBA embodies the art and science of "self-healing." Help desk and service desk products generally serve as a single point of contact for incoming incidents, which are effective for tracking and ticketing incidents, problems, and change processes. However, they do not run automated recovery and resolution procedures—those mostly manual, largely error-prone tasks. RBA will triage, diagnose, and repair those issues it's programmed to resolve without manual intervention—unless warranted. RBA advanced dashboard capabilities allow for customizable views of prioritized events.
Event Resolution
Event resolution mechanisms correlate information for presentation in a concise, effective manner for the hand-off to support personnel. A single-source root cause is determined, and IT personnel are trained specifically on that area. Frontline operators then take action to perform automatic diagnostic across applications, servers, and network entities.
Exceptional events present problems that require the extensive analytical skills of trained professionals. There are many arising error conditions that are easily addressable through automated workflows. RBA interconnects multi-vendor products and aggregate data for delivery to the appropriate response staff.
Process Documentation
RBA tools increase added value by automatically capturing information for RBA procedures at every step and the automation workflow in aggregate. Captured information details and describes how each workflow is executed and concluded by the RBA system and stored in its database. Additionally, RBA tools can automatically create documentation from existing flow deployments, particularly wherever it hands-off to IT support staff. Documented processes and procedures go beyond capturing platform versions, serial numbers, and detailed hardware configurations. Various host interactions, account additions, databases locations, and maintenance cycles are also part of the documentation and provide important information about what to do with affected systems or software. Automatic remediation "self-healing" procedures are made less effective without definition of events and documentation of all applicable workflow procedures.
Once created, IT professionals select an option to create step-based documentation performed at each point in the workflow procedure. This feature better enables IT operators to focus on rapid authoring and delivery of workflow automation, instead of peddling backward to meet timeconsuming content authoring and process analysis requirements to generate relevant documentation. Integration capabilities leverage the Configuration Management Database (CMDB)—a special global database used to store configuration data and gauge real-time views of changes—as a problem management tool, allowing network operators to access configuration data in real-time and incorporate such data into automated workflows related to triage, diagnosis, and repair as they see fit.
Follow-Up Procedures
RBA solutions perform a post-operative follow-up on completed procedures to ensure the correctness and compliance of implemented event resolution workflows. RBA monitors the progress of ongoing workflows to establish a continuing and thorough incident resolution cycle.
At each step along the way, RBA tools examine event resolution procedures for further problems, then issues Help desk trouble tickets if such procedures fail to complete successfully. Upon successful completion of a resolution workflow, the system identifies that the situation is resolved and adds appropriate details to the ticket text before commencing its final, automatic close-out.
RBA Enables Ongoing Automation of New Tasks and Fine-Tuning of Existing
Automation
RBA orchestrates and automates IT operations management processes, ultimately unifying communication among underlying and supportive management tools. This applies equally to enabling ongoing automation of new tasks, which results in scalability that fine-tunes existing automation practices and procedures.
Generically, an event resolution scenario is describable as follows (illustration provided in Figure 3.1):
- New server outage
- Acquire incident details, check status and ownership, etc.
- Assign remedy incident
- Query CMDB
- Invoke configuration management: provision standby server
- Update remedy incident
- Test server status
- Success: run diagnostics
- Failure: escalate remedy incident
- Close remedy incident
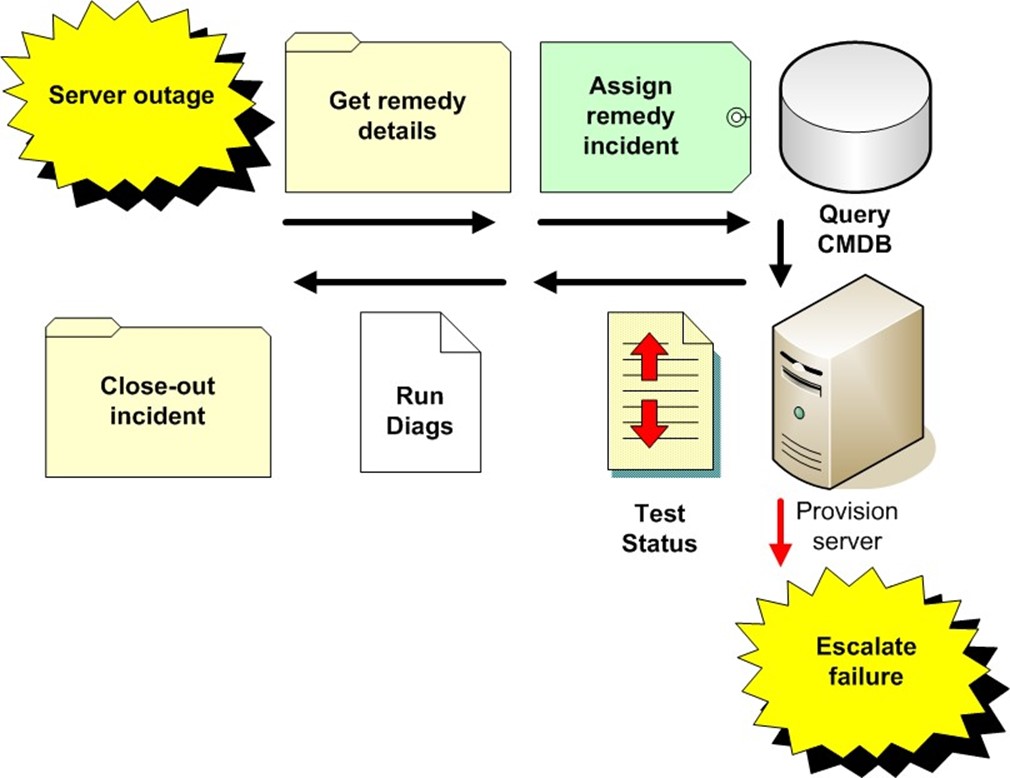
Figure 3.1: A generically described visual flow depicting automated incident resolution.
When RBA systems are properly implemented, tribal knowledge no longer leaves the company with those employees who move onto other venues or opportunities. Visually guided scripting tools empower non-programmer personnel to automate sophisticated management and maintenance tasks. Automated remediation procedures benefit Help desk and technical staff, particularly during disaster recovery (DR) scenarios by performing examinations, gathering information, and executing reparative or restorative actions.
Case 2: Orchestrating Complex Changes
Any given large-scale IT environment supports hundreds to thousands of concurrently running applications, services, servers, and end users. In this environment, prepared organizations utilize well-documented processes and procedures to implement change requests in a coherent and consistent fashion.
In most cases, other organizations operate from undocumented or outdated (and possibly outmoded) processes and procedures. Such methods send IT operators scrambling when bad configurations, broken applications, failed hardware, or unavailable services foment production or operations issues and problems. RBA can trigger a CMDB and helps staffers to understand the risks of change and how changes can affect resources in production environments.
Change orchestration creates and applies uniformity to change management processes and procedures across all tiers of an organization's infrastructure. It enforces process compliance, enables automatic audit trails, and facilitates end-to-end change automation. In the absence of process automation, change orchestration and incident management processes lack consistency and produce high-alert volumes. They also create lots of recordkeeping and checking work, as responsible parties must do by hand what RBA systems can do as an integral part of the normal everyday operation.
In practice, RBA can handle virtually any workstation provisioning tasks and manage administrative alert volumes, thereby freeing support personnel to pursue other, more productive activities. Overall, this results in a more efficient and productive workforce. It can also help organizations realize tremendous savings in annual labor costs. Organizations that implement RBA workflow procedures benefit from three primary advantages with respect to automating change and configuration management tasks:
- Enables IT operators to consistently execute automated change management procedures, as captured and facilitated by RBA tools
- Improves overall cost efficiency of IT team members by eliminating manual and errorprone procedures through automation
- Increases IT agility and business responsiveness with respect to provisioning new systems and infrastructure, enabling IT departments to react more quickly to changing business needs and trends
Certain business markets (such as the healthcare industry, health insurance companies, financial institutions, and so forth) are subject to continuous regulatory changes and to often costly, if not onerous, compliance monitoring and reporting requirements. This occurs alongside arising competitive opportunities to stay afloat or get ahead, which may involve significant changes to properties or procedures to IT management or operation. These companies require ultra-lean administrative processes to efficiently and reliably process thousands of transactions daily while quickly adapting to meet evolving conditions.
Change Design and Planning
Gartner research estimates that operational error results in about 40% of all system or service outages. Cheaper technology costs drive increasing hardware and software acquisition, but the number of support personnel that oversee and operate these components remains relatively constant. In effect, you end up with roughly the same amount of people performing increasing numbers of tasks and acquiring more on-the-job duties, obligations, and responsibilities. This affects their availability for ongoing or upcoming tasks and increases the likelihood of man-made errors. What better opportunity exists for shifting what is currently human labor to RBA?
Initially, RBA monitoring agents identify specific conditions (such as changes and events) and then perform a configuration audit for indication of any change requests. When a change request is issued and performed, the RBA system follows-up to check device compliance. Upon noticing any unresolved situations, it automatically issues a trouble ticket. Upon resolution, RBA tools add appropriate details to the open trouble ticket before final and automatic close-out.
Pilot Testing
A pilot testing procedure examines and ensures that newly created or recently modified workflow procedures execute as planned and produce the intended results. Pilot testing involves a battery of validation and verification processes that walk through each workflow step by step and reports any operational issues or discrepancies discovered along the way. A sandbox or simulator component in an RBA system is a highly desirable feature and provides the kind of security and confidence in thoroughly tested processes that can be unleashed in production environments. Inside a protected test environment (the sandbox), workers can test pilot workflows without impacting actual resources within a production enterprise environment. Pilot testing is a key capability within RBA solutions that is worth serious consideration as well as further exploration and investigation in terms of its organizational footprint and how it helps to meet enterprise-specific needs.
Resulting Visual Workflows
RBA creates a visually guided workflow, charting each process along a path of tasks and procedures from start to completion, with branches for various states (success, failure, issues raised, and so forth) along the way. Mechanisms document procedures as they impact and interact with systems and network components, detailing successes or failures and visual indications for every action taken as well as for tasks left undone.
Workflow procedures are documented with visual icons and status indicators that re mapped into one or several linked diagrams. Reports on real-time statistics can be displayed through configured charts, tabs, and tables. Figure 3.2 shows a relatively simple visual workflow that includes various types of icons to identify activities and task outcomes, along with the kinds of transitions or state changes that link them together.
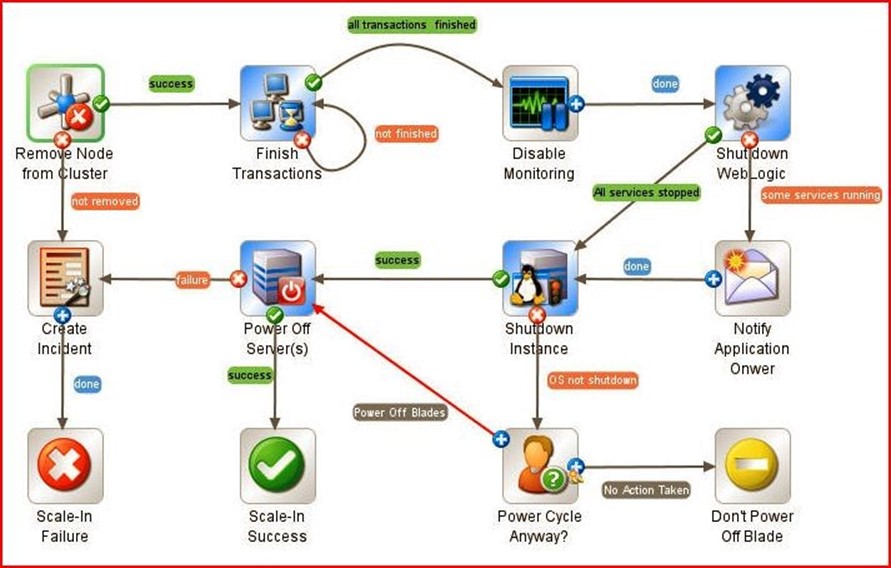
Figure 3.2: An example workflow showing the process of adding computing resources to a specific application tier in a clustered server environment. Note the icons used to label (success, failure) or to identify what kind of action is involved at each step.
Complete, Consistent Deployment (Automation)
A CMDB enables administrators to visualize changes to a database, understand potential outcomes, and notice changes that affect applications. Administrators can then orchestrate other processes to effect a more positive change when an incident negatively impacts resolutions or workflows.
The only way to a complete, consistent deployment strategy is through a carefully crafted automation workflow that takes into account all possible resolution measures before issuing any handoff to IT support personnel.
Complex Application Changes
Most IT environments involve heterogeneous techniques, technologies, and tools. Capturing complete and comprehensive RBA oversight for IT operations for thorough integration is always a complex challenge. There are a vast number of installed products and platforms and the particularly problematic parts often involve (or encapsulate) legacy and homegrown applications and infrastructure. Writing integration modules for every possible scenario and each test case can be daunting and highly problematic. Without easy integration among the systems being automated, IT personnel may find themselves relegated once again to piecemeal scripting tasks—which is precisely what RBA seeks to obviate.
As laws, regulations, and competitive landscapes change, so do applicable business IT operations. New or modified applications may supplant existing features and functionality or alter the way certain procedures are handled. Under an existing IT infrastructure comprised of legacy applications and homebrew platforms, this task is an overly complex administrative and management nightmare. Under an RBA-managed infrastructure, legacy tasks and in-house arrangements can be integrated into a contiguous, closed-loop life cycle monitoring and management platform.
Unity among working parts and uniformity among procedures in a heterogeneous environment is achievable through the creation of an organizational footprint or portfolio of individual tasks and their designated workflows. RBA provides this and the pilot implementation and subsequent adaptation of new changes, modifications, and versions before the official launch party kicks-off. Once all hang-ups, kinks, and snags are worked out, the pilot installation shifts directly into the production environment.
Servers
Server automation provides life cycle management for enterprise servers and server applications across infrastructure elements. Systems distributed across several data centers are managed by a diversity of teams that demand greater accountability, agility, and flexibility to effectively manage change.
Administrators can automate a broad range of tasks including network or service discovery, server provisioning, configuration management, patch distribution, script execution, and compliance assurance. RBA also automates operations and processes on systems across the enterprise to provide an integrated and elevated vantage point over their operation.
Network
Automating network systems keeps management costs down and productivity levels up while providing the instantaneous responsiveness and quality service the business demands. A comprehensive RBA framework unifies third-party network management elements to deliver preventive network management that proactively eliminates security breaches. At the same time, it addresses critical IT issues (for example, service availability, device connectivity, bandwidth utilization) by decreasing network complexity and improving network stability.
Regulatory and statutory compliance enforcement aligns with IT security and organizational practices. This enables IT governance initiatives, automates delivery of change request control processes, and provides automated management over compliance and security best practices. Visual analysis is assisted through automatically generated and well-detailed diagrams of the network topology to facilitate troubleshooting procedures. A thorough perspective over networkwide dependencies provides valuable insight when diagnosing layer-2 and layer-3 relationships. Thus, for example, it might make sense to add troubleshooting steps for VPN connections when remote users experience application delays or problems because problems with a VPN connection can produce those symptoms, even though they probably have little or nothing to do with the application involved.
Storage
Archives, backups, and replication are vital processes to the IT environment's subsistence. Storage process automation maintains security and privacy compliance in accordance with applicable laws and regulations while optimizing asset utilization and productivity levels. RBA is primarily tasked with automatic document generation, so companies are assured of "doing the right thing" when storing confidential or sensitive data or creating mission-critical backups.
Storage process automation enforces policies and documents procedures for storage operations. Through RBA, this can be applied consistently across the enterprise without requiring individual storage unit preparations. Furthermore, these processes, practices, and procedures facilitate successful compliance and security audits.
Orchestration in Specific Ordering
Certain tasks can be executed concurrently, which some RBA systems support, but the final resolution process usually requires comprehensive control in the final execution and convergence of task completions. However, substantial performance gains are achieved where processes run concurrently, executing serially wherever a sequence of workflows is dependent on sequential ordering.
RBA software requires intelligent orchestration capabilities to initiate action within third-party platforms and products. The orchestration engine operates in concert with integration capabilities to interpret results of RBA actions to determine subsequent steps and either log or report each step of the process. This capability is paramount for tracking change requests and maintenance procedures that involve multiple (and possibly multidisciplinary) systems and impact service availability. Run book orchestration is an integral component for providing mechanisms that enable design, build, and monitoring tasks to facilitate IT operations workflows.
Intelligent process workflows posses the necessary rules to check state at each step of the workflow procedure and forks to another workflow branch when specific conditions are met. It can roll back to a previous steady state upon encountering a failure condition or create and issue a trouble ticket when no resolution is defined and RBA has no further suggestions.
Case 3: Automate Repetitive Tasks and Activities
Newly occurring or periodically recurring IT tasks (such as data backups, resource replication, server provisioning, and update deployment) can be captured and automated using RBA. Multiple copies of data stores (address books, directories, and customer databases) can also be synchronized in aggregate using RBA tools. RBA effectively rides shotgun alongside task and activity-driven workflows to observe procedural execution and to generate documentation at every step of the way.
Reducing manual interventions and lowering inherent latency (especially in the form of idle wait-states at the hands of pending or incomplete procedures) in server provisioning—whether they run AIX, BSD, Linux, Solaris, UNIX, Windows, VMS, or even VM—is a key selling point for any turnkey RBA solution. Standardizing a server provisioning process to meet internal auditing demands and regulatory compliance needs can also deliver substantial and important benefits.
Specific IT needs are identified and explored to establish process development, integration, and subsequent closed loop orchestration. RBA's asset management tools (including validation and tracking of components) and its change request and information gathering mechanisms facilitate organizational deployment across physical and virtual infrastructures. A hypothetical example of this process can be summarized as follows:
- Submit a change request—The RBA solution provides an integrated self-service portal tied into a backend remedy system. Data is manually processed by the IT department.
- Collect and verify information—Gather all data and initiate one of three select provisioning activities to build the server system. IT "assembly line" workers update the initial change request throughout various stages of "assembly."
- Completion phase—All provisioning tasks are accomplished and changes are subsequently recorded as part of the documentation process in the asset management system (usually ITIL and/or CMDB).
Let's examine the scale and scope of RBA in terms of automated activities.
Capturing and Automating New Tasks
RBA tools make repeated handoffs to support staff particularly when dealing with new tasks or unanticipated outcomes that require analytical skills. For server provisioning, RBA systems make repeated interactions with system integrators for handling individual hands-on tasks that satisfy a given change request process. Self-documenting features enable IT workers to indicate their successes or failures and notify subsequent higher-level administration or oversight staff for review as needed or as mandated. Furthermore, this facilitates eventual hands-free automation of recurring processes and procedures while ensuring and enforcing compliance policies.
When dealing with high-priority and highly sensitive disaster recovery processes, automation of repeat procedures and support tasks improves IT response time in re-establishing functionality to a faltering enterprise. Other examples of conditions that may be addressed via RBA:
- Starting, stopping, and restarting services at timed intervals
- Rebooting and reconfiguring file or print servers
- Creating users and changing passwords
- Performing log rotation, scrubbing and monitoring
- Running periodic database defragmentation
In addition to automating key ITIL processes, it's apparent that RBA applies equally to other common and repetitive maintenance procedures as well. Automating these routines frees-up key resources to better focus on strategic tasks that may require special attention and critical thinking skills. Such routines are time consuming when performed manually, typically batched by job scheduling mechanisms, and produce well-understood processes and predictable outcomes. It is because of these predictable sequences and predetermined functions that RBA is made entirely practical. A few descriptive examples appear in the following sections to further illustrate this process; examples are based on backup and replication, disaster recovery, update deployment, fix/patch integration, and so forth.
Backups and Replication
RBA solutions provide tools for automating the backup and transfer of valuable data, vital databases, and key system elements that drive business. Moreover, all this is possible without authoring new scripts, issuing batch processing, or deploying custom programs.
Backup jobs are executed in an event-drive fashion and coordinated alongside other systemspecific services (for example, starting, stopping, and restarting applications or services). All complex administrative tasks and maintenance activities can be coordinated including: cleaning up temporary files, initializing worker threads, and notifying operators in the event of report creation failures.
Disaster Recovery
During the development of disaster recovery plans, it is as important to recover the entire enterprise as it is individual systems. The creation of run books that document all functional areas within IT—including applications, databases, networks, and servers—is crucial to a welldefined recovery strategy. Together, both operate hand-in-hand to give your organization a detailed process to follow when re-creating systems and protecting business from any sizeable disaster.
RBA has a self-healing discipline that triggers alerts and kick-starts fault remediation and failure restoration processes when things go wrong. This includes when things go terribly wrong, such as natural or man-made disasters that disrupt business operations. RBA solutions fulfill disaster recovery strategies for enterprises of any size, enabling rapid implementation of high-availability and recovery processes across heterogeneous hardware and software environments—including virtualized contexts.
Update Deployment
IT update deployment is a general process that is tailored to specific requirements or characteristics according to conditions and situations. The general deployment process consists of several interrelated activities with potential transitions between each one. Every platform and product is different, so a multidisciplinary IT environment must individually address update procedures and processes that may prove difficult to define and deploy consistently.
Deployment activities include system assembly and preparation, software installation and insertion, activity initialization, service activation (or deactivation), environmental adaptation, and version tracking. RBA maintains comprehensive control over all automatable update deployment workflows and makes the hand off to support staff wherever necessary.
Fix/Patch Integration
Like update deployment, bug fix and patch integration is an application, service, and serverspecific process. A typical procedure may require application closure, service stoppage, patch integration, and subsequent restart. Fixes and patches can be batch scheduled and collectively deployed among groupings or departments of computers.
As the environment acquires new equipment or adapts to changing conditions, a simple distributed patch integration process easily breaks. With RBA workflow procedures, metadata between automation workflows and the target environment factor into integration procedures. This metadata captures the current state of affairs for the target environment alongside historical data for comparison and analysis purposes, and sidesteps the problem of erroneously fixing or patching incorrect software or service versions.
Multiple Data Store Copy Synchronization
RBA enables IT operators to dynamically manage dispatch and execution of run book workloads and automate responses to operator requests. This includes synchronizing parallel processing of database backups and data replication workflows across platforms and programs to reduce scheduled downtime and multiple-copy conflicts.
Like processes, data-related automated workflows may run concurrently and therefore require a logical yet transparent means of maintaining multiple differences to the same or interrelated workloads. Synchronization tasks include batch file synchronicity, relational database replication, resource reconciliation and concurrent data updates, and service or software information.
Remove Error-Prone Hands-On Interaction
Fewer manual interventions equal less operational errors. Unplanned downtime and unintentional mistakes are controllable and preventable to a great extent under a proper RBA platform. Conceptually, process automation starts from a customized or existing procedure and test piloted before deployment in the enterprise. At this phase, most (if not all) anticipated problems are flushed-out and resolved during dry practice runs. Then, any further issues— perhaps those unanticipated and unforeseen—that arise during deployment are encountered and addressed.
RBA facilitates the development of repeatable, reliable workflows that remove operator error by learning to perform a routine once and perform it correctly forever afterward. It therefore eliminates the exponential potential for human involvement to negatively impact business by introducing absent-minded or careless errors—entirely preventable issues. Additionally, RBA documents procedures and enforces compliance for executed workflows, eliminating yet another time-consuming manual process for junior operators.
Documentation and Detailed Audit Trails
On the subject of documentation, workflow definitions and descriptions are necessary to eliminate the potential for tribal knowledge negatively impacting the business when "tribesmen" leave the company. Detailed audit trails are also automatically generated as part of the ongoing RBA management process to meet IT governance and regulation best practice goals.
Documentation often falls by the wayside in the wake of urgent, unhandled exceptions and events at various levels of enterprise. It is this surge of alerts, events, and incidents that RBA seeks to better prioritize for efficient and effective management practices.
Change Logs
Another critical aspect of the ongoing life cycle maintenance process includes change log upkeep. Change logs are electronic track records for implemented changes—configurations, updates, and so on. Logging and reporting each step of a change request workflow is essential to reviewing and reworking procedural execution.
Control over change request aspects requires an intimate knowledge and track record of modifications and revisions to existing elements of the business infrastructure. Keeping track of these items manually is unreasonably wasteful of time and human resources especially where IT staff is increasingly burdened with more expectations and responsibilities.
Update Information
As the nature and needs of business change, so too do its functional elements. Administering change requests across a dynamically changing platform and program base creates complex challenges for human operators but represents a basic capability of RBA solutions. Occasionally, supportive process automation equipment is replaced and, when centralized database management is well-maintained, there is no margin for uninformed IT operator error.
Updated information includes hardware change-outs, server rebuilds, and any other typical service ticket item encountered in the field. When necessary, the system interacts with the operator to provide detailed or analytical input and help close-out remaining manual procedures.
Case 4: Customizable Workflows by Example
By intention, the examples provided so far in this chapter have been broadly described and generically conceived. Their purpose is to maintain consistency with the high-level overview we present throughout this work. In the passages that follow, you will find a few more specific examples that include visually guided workflow illustrations to help you grasp the concepts we examine more fully.
Model workflows capture meaningful tasks in the context of your work environment: they might involve responding to a downed server, dispatching its replacement, then continually monitoring its health over the long-term. Such tasks are also easily and often repeated throughout the course of routine maintenance, and are therefore ideal subjects for automation workflows. Let's explore some illustrated examples in the sections that follow.
Application Tier Scale-In
Commissioning new and decommissioning old application server platforms is an everyday part of maintaining a growing and active business IT infrastructure. Run book procedures can automate various aspects of these and other processes whether the target is an isolated, individual platform or represents a cluster of systems that may involve a handful of individual servers or an equal number of server blades. Application tier scale-in is the process of providing visually aided automated workflows to address such issues.
Notice the sample application tier scale-in workflow depicted in Figure 3.3. It begins by removing a specified node from the target cluster. If any failures occur along the way, an incident report is generated; successful completion advances along to finish remaining transactions. Upon successful completion of this task, the workflow disables monitoring devices, deactivates Web logic, and halts all services, before shutting down the server instance and powering off the server unit. Once the node is restored, the server cluster will be restarted and can get back to work unhindered by a downed element.
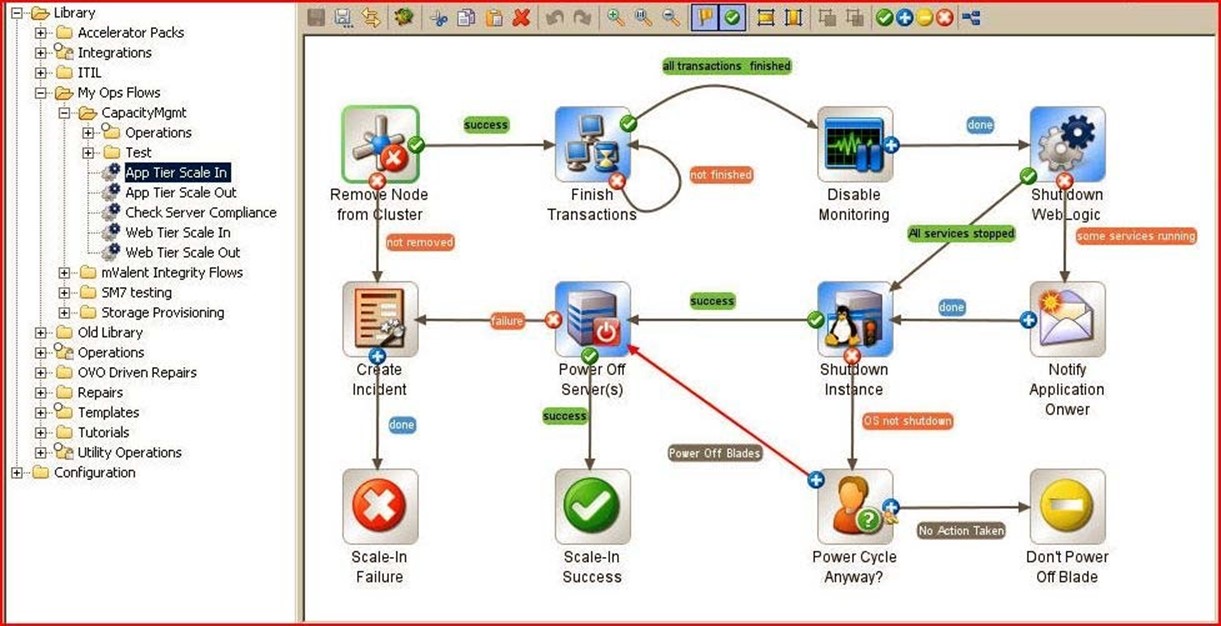
Figure 3.3: An example workflow providing application tier scale-in for the enterprise.
Server Monitoring Automation
Maintaining recent and refreshed network-wide server state awareness may be accomplished using regularly updated status reports. These reports might require gentle poking and prodding into platform-specific process logs and run-time records, or issuing simple queries to key network-centric management databases. Another prime example where manual processes can be automated and tribal knowledge captured and represented for ongoing, transparent re-use occurs in the context of central server management.
Performing system health checks is a routine and necessary task when keeping tabs on particularly large and diverse networks. Figure 3.4 illustrates an example of remote server status monitoring for a Red Hat target platform. The process begins by pinging the host to check for accessibility, then checks remote uptime for duration of availability before checking the last time a log message arrived along with other platform-specific details. Notice that throughout this process, failure at any point will automatically notify event-handling personnel that hands-on resolution may be needed. But when this process can complete without problems, it takes the load entirely off the shoulders of personnel on duty, freeing them to perform other tasks.
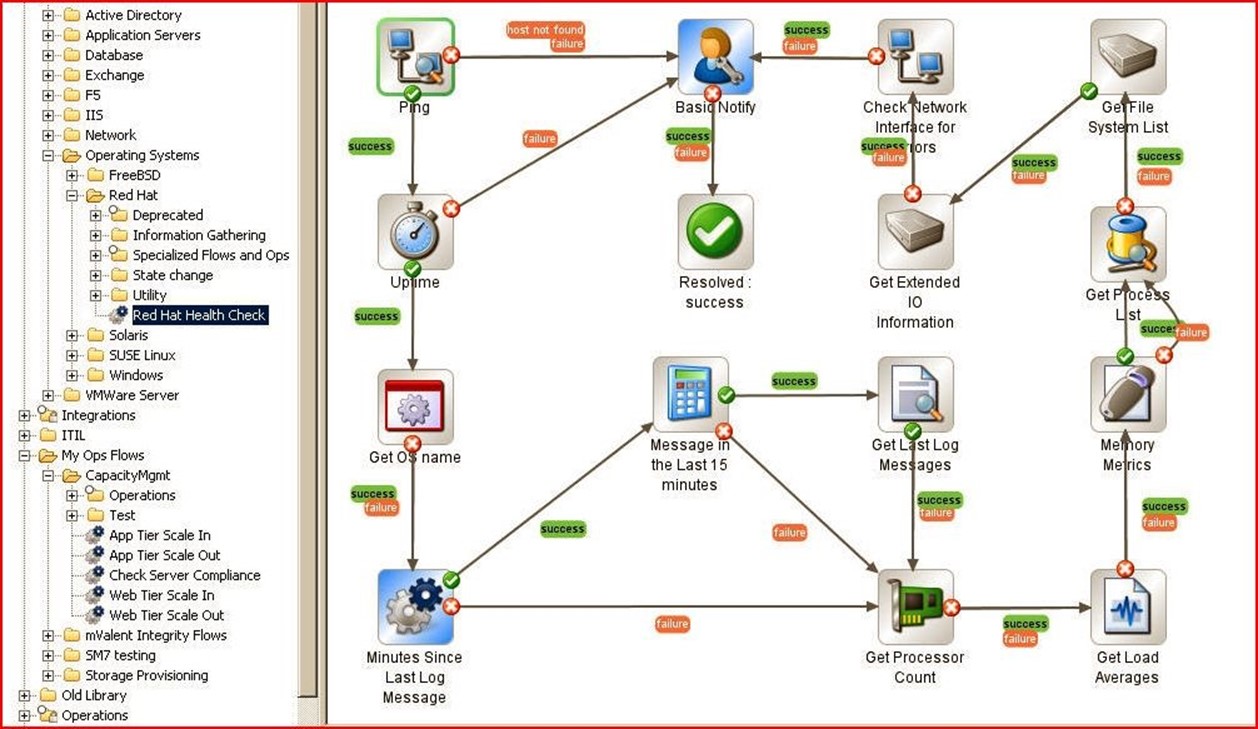
Figure 3.4: Automated server health monitoring is just a visually-guided workflow away.
Server Provisioning Automation
In the shift from managing discrete applications and devices to delivering tightly integrated enterprise services, IT must balance infrastructure flexibility against uncompromised accountability. Also, IT must adapt to a growing diversity of systems and evolve to capably manage all of them seamlessly and coherently. Automation can be instrumental in attaining this balance and in helping organizations to achieve greater operational accuracy while handling high-priority needs and improving overall personnel productivity and efficiency. In this case, provisioning, patching, and remediation procedures for the servers involved help define the workflow processes that will be put to work.
As Figure 3.5 shows, server provisioning automation software obtains job information and enters a loop through software policies in search of name matches, host entries, and related custom attributes. It then leapfrogs through provisioning custom applications, storage, and a target server before concluding its job approval resolution phase. Here again, as long as routine tasks complete successfully, operations staff need only schedule or trigger such workflows, and RBA systems can handle the rest of the work involved, without missing any key details or entering any incorrect setup data.
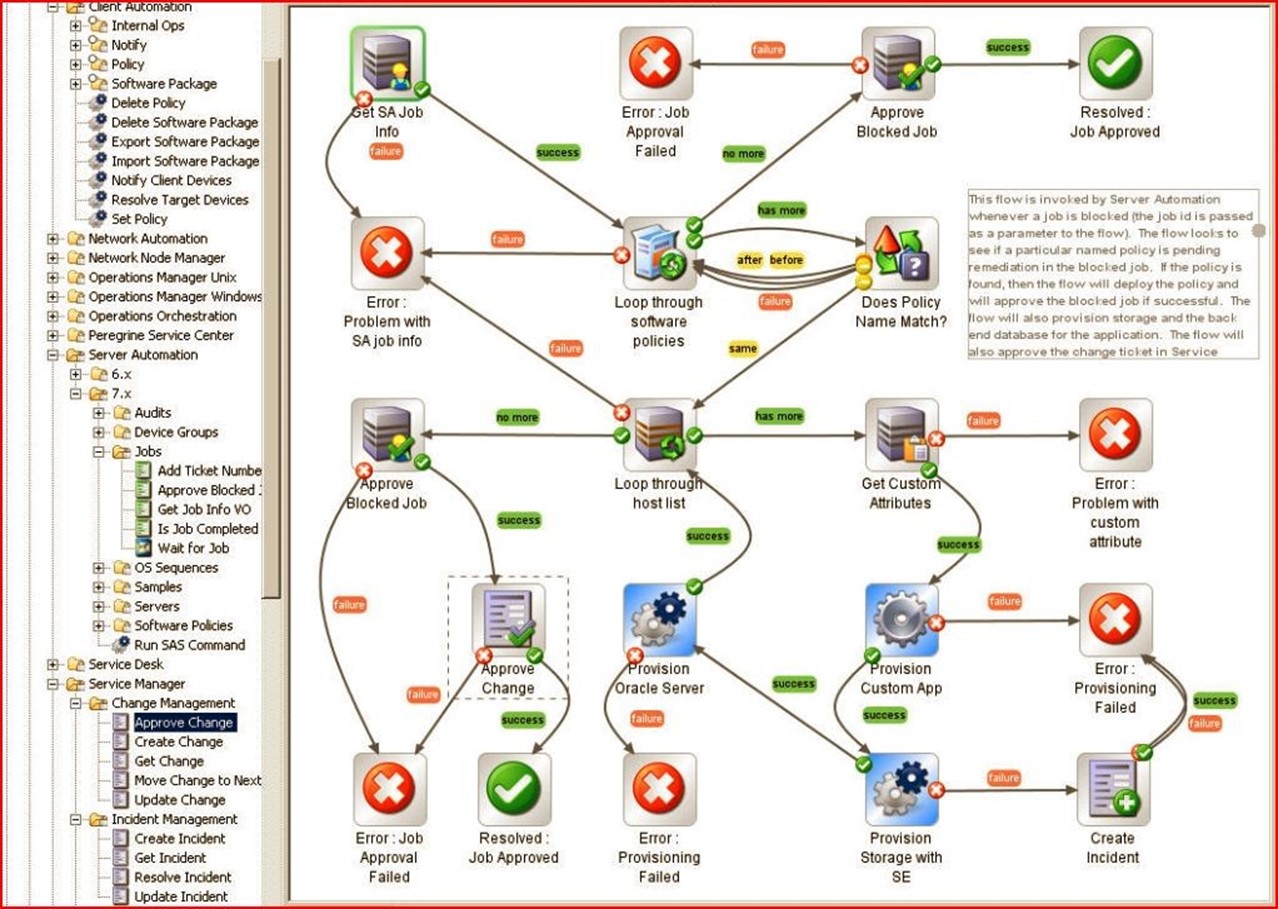
Figure 3.5: The automated server provisioning workflow illustrated.
The Real Return on RBA Investment
When it comes to understanding the real returns on RBA investment, the forgoing examples can do a lot to add substance to claims that RBA helps to reduce staff time investments, speed problem resolution, increase productivity, and integrate IT processes across multiple platforms, networks, and applications. Though there is effort involved in codifying and creating highly customized workflows, most well-built RBA systems include sizable libraries of predefined workflows for common tasks such as backups, directory synchronization, patch and update deployment, disk defragmentation, and so forth. With a strong and usable library of workflows at its disposal, enterprise IT will find itself better able to take care of routine business, resolve common problems and issues, and spend more time thinking about and working on what kinds of systems and services it should be providing in the months and years ahead. Though payback for RBA will often be measured in other terms as well, these returns on RBA investment should not be overlooked, nor their value understated.