Virtualization Automation—The Service-Centric Approach
Virtualization Automation—The Service-Centric Approach
The previous chapter spoke of virtualization from within the context of service automation. Viewed from within the lens of process frameworks such as ITIL v3, virtualization and the automation benefits it natively brings to the table assist the smart organization with service fulfillment across their entire life cycle:
- Service Strategy. Data analysis, including performance and metrics analysis across virtualized workloads, can be used to identify areas in need of additional services or augmentation. The improved visibility gained through virtualization's common basis across all services provides strategy teams with better data to make decisions about where to apply resources.
- Service Design. Once identified, the speed of design of new services is enhanced through virtualization's ability to roll configuration changes backwards and forwards at will. Virtualization's snapshotting and rapid deployment capabilities provide service design teams with a more flexible platform upon which to fine tune designs before rolling them into production. These capabilities flow well into testing requirements as well, as virtualization's platform enables test environments to be quickly reverted back to nominal states at the conclusion of each test phase.
- Service Transition. Once ready for movement into production, virtualization elevates the level at which individual configuration items are logged by configuration control. With the virtual machine template capable of becoming the configuration item over and above
- the individual configuration setting, the level of effort involved with service documentation and change control is reduced. Validation activities prior to service operation gain the same benefits as seen in the testing phase.
- Service Operation. Services in operation require regular care and feeding, the action of which can be a negative impact on workloads if not undertaken with careful precision. Virtualized workloads have the capacity for invalid changes to be rolled back when necessary, returning the environment to a pristine state with little impact to service quality. Additionally, the resiliency of services during non-nominal conditions is improved through virtualization's enhancements to backup and restore as well as the disaster recovery processes.
- Continual Service Improvement. Lastly, throughout all these steps is the constant need for gap identification and resolution. With the right management tools in place, metrics between templatized virtualized workloads are more easily measured against each either and against those in the physical world. This data gives service improvement teams the hard data they need to locate areas of improvement.
Although these automation improvements are a natural function of virtualization itself, they don't necessarily arrive with the tools natively associated with virtualization platforms. Enterprises that leverage platform-specific tools alone may not be able to recognize all these benefits.
The right tools are indeed necessary to handle the management of virtualized workloads as well as manage the gathering and later visualization of this data. Metrics gathered through specialized management utilities discussed in the next section have the capability of analyzing workload performance, capacity, and behaviors across multiple servers and services. Only through the effective analysis of these metrics in relation to environment needs can business services be appropriately improved to meet the ever-changing needs of business.
What Is the "Service-Centric Approach"?
To truly understand how this information is best gathered and analyzed across the whole of the enterprise IT environment, it is useful to look at a real-world example. Consider the large organization that over time has implemented virtualization in a stepwise fashion based on the needs of individual projects. As point solutions, those projects selected their virtualization platform based on the needs of the day in comparison with the requirements of the service itself. Their decision on the software solution actually used to power the virtualization layer may not have been based on those used for other projects elsewhere within the organization. Additionally, while some services' workloads have been moved atop a virtualization platform, the enterprise itself may continue to support a significant physical server presence as well.
This situation is not unlike what is experienced in many large-scale environments today. Rare is the organization that makes a comprehensive decision to host all service workloads atop a singular platform—irrespective of physical or virtual. Individual project teams are often given guidance in terms of virtualization platforms of choice, but the determination of which is selected is often left to the individual team.
Because of this situation, over time, many enterprise organizations find themselves suffering under the weight of supportability needs for each of these platforms. As Figure 2.1 shows, the long-term result is that Service A finds itself relying on Virtual Platform A for its processing. Service B rests atop Virtual Platform B. Other services, marked C and D in the figure, remain in the physical state and require altogether different management tools still.
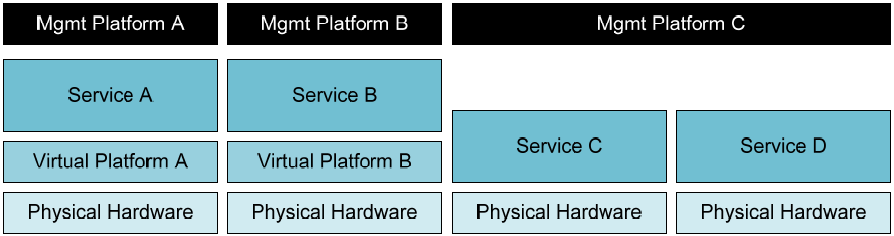
Figure 2.1: Multiple virtualization platforms require multiple vendor-specific management platforms. These can be different still than those used for managing physical workloads.
This point is crucial: Although virtual workloads in the design and transition phases are by definition concerned with their own processing, those in the operations phases must be managed alongside others already in production.
Although handy for the quick spin-up of individual projects, this horizontal scaling of management platforms grows to become an excessive cost to the enterprise organization. Left ungoverned, point solutions for virtual platforms—along with their management requirements— can grow in number to the point where operations teams find themselves managing innumerable platforms. Each platform comes with its own set of administrative functions, interfaces, and siloed data that is difficult to compare across services. Ultimately and without resolution, the end result is diseconomies of scale across the operation of all IT services, reducing virtualization's overall efficacy in the environment. Or, more simply put, more management platforms equals less manageability. Organizations that experience this situation quickly lose many of the benefits discussed in Chapter 1 while at the same time seeing added cost.
In the context here, the Service-Centric Approach is coined to identify a management mindset that layers atop existing platforms, regardless of whether they are physical or virtual. Servicecentric management solutions in this space provide a comprehensive and cohesive management interface to all services in the environment. Figure 2.2 shows how a potential service-centric management solution can layer atop an interface with virtual and physical resources to integrate their data collection, centralize their management functionality, and provide a unified interface for teams to interact with them.
As you'll see in the image, such a service-centric management platform would include integrations into multiple layers of individual business systems, at times directly connecting into the physical hardware or individual service interfaces. At other times, the platform may integrate with product-specific virtual or physical management platforms for management of the resources beneath that platform. A service-centric management solution is designed to include this widespread reach in order to get its arms around services from multiple layers. The end result of adding this management layer atop others in the environment is a unification of administration capabilities as well as enhancements to the monitoring of key metrics.
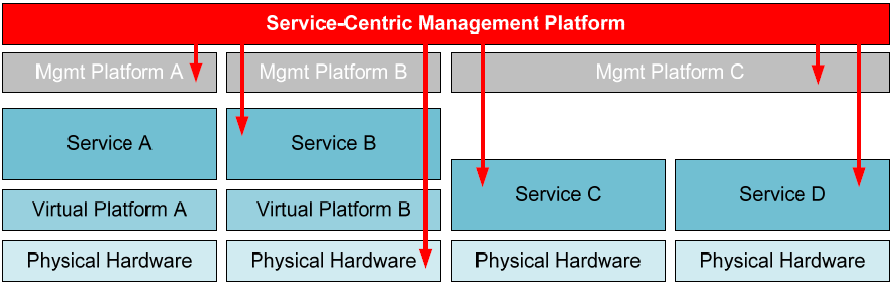
Figure 2.2: A service-centric management platform layers atop existing services and their management platforms. Its wide reach integrates with business services at multiple levels, enabling a centralized source for management and data gathering.
It is worth mentioning that service-centric management integrations needn't necessarily stop at the layer of physical or virtual server hardware. Networking, storage, and other elements of the IT environment are likely to have integrations as well.
Service-Centric Management's Impact on Enterprise Operations
When considering the possibilities gained through the use of a unified platform such as the service-centric approach, there are a number of impacts on operations that immediately become evident. As a primary impact, enterprises previously awash in multiple management interfaces due to the accumulated decisions of service delivery teams can now unify their operations under a single banner.
Unification of operations removes many of the concerns stated in the previous chapter associated with standardization. Standardization is a worthwhile goal for every enterprise, with vast economies of scale and cost benefits gained by focusing on a single source for a particular function. Yet moving exclusively towards a single source in some situations eliminates the ability to realize per-product advantages. Some vendor solutions may incorporate feature benefits over others in particular situations. Other platforms may leverage functionality or architectural superiority that outweighs the cost savings associated with blind standardization.
Consider the various virtualization architectures available on the market today. Hardware virtualization is one solution that provides a common hardware base across all virtual machines. That common base ensures that virtual machines of the same operating system (OS) are equivalent no matter which virtual host processes their needs. Yet this commonality comes at a price. The level of resource emulation required by some types of hardware virtualization imposes resource overhead, reducing the raw performance of all virtualized workloads.
In comparison, the architecture associated with OS Virtualization gains significant advantages when virtual machines are highly equivalent in configuration. In this specific case, OS Virtualization's use of real resources—as opposed to emulated—along with its heavy use of delta copies between hosted virtual machines results in a higher level of performance for certain workloads while requiring fewer resources on-disk.
The service-centric approach enables enterprises to standardize on solutions that work best within their scope of applicability. At the same time, it enables alternative solutions to be similarly supported when it is appropriate to introduce them into the environment. In all cases, the service-centric management approach provides a unified management interface for administering solutions irrespective of vendor or platform.
Impacts of the Service-Centric Approach on Data Center Management
Data centers and the teams that mange them exist under the daily stress of ensuring that business services remain up and operational. That charter for high availability grows difficult when the count of interfaces required to administer the environment grows large. When Virtual Platform A requires administration through one management widget, while Virtual Platform B requires its administration through yet another, operations teams unnecessarily expend extra resources in the management of the entire environment.
Those extra resources relate to not only accomplishing the actions required for the environment's daily care and feeding but also other necessary functions such as identity and access management, performance management, monitoring and alerting, and scripted actions. Later, this guide will discuss these necessary activities in more detail. For now, know that a service-centric approach reduces the number of touch points for data center managers, which improves their productivity as the environment grows large.
Impacts of the Service-Centric Approach on Service Strategy and Planning Activities
Most importantly, the integration of data collection interfaces across multiple layers of the environment enables metrics to be measured across services. The service quality being seen with virtualized services can be easily measured in comparison with those that remain hosted atop a physical infrastructure. Virtualized services can be measured in comparison with other virtualized services. And, above all, the dependencies of services can be measured in comparison with desired overall service quality.
All this discussion on service quality and desired levels of service quality relates to ways in which an IT organization can realize the fulfillment of its Service Level Agreements (SLAs) with the business. With data that is of higher resolution across more elements in a service, IT will develop a better situational awareness of its environments under management. Better situational awareness translates directly into an improved capability to fulfill its mission of service availability.
As an example, think about the types of IT dependencies that typically interact with a particular business service. That service may reside on a physical server or a virtual one. It likely requires network connectivity with good quality in order to process its mission. It may require a storage subsystem for keeping and processing its data. If virtualized, it may be collocated with other business services atop a virtual platform. In the platform-specific approach, the metrics used to measure quality of each of these elements are segregated by platform. They may measure at different rates or use a different format for the storage of their data. Aggregating data across each individual dependency can be problematic and may be operationally impossible if real-time data is desired.
In contrast, the service-centric approach includes integrations into each subsystem. Those integrations natively include the translations necessary to pull quality metrics from each subsystem. Once pulled, it can store them in a centralized location where cross-subsystem reports can be created. Those reports can then be used for enterprise-wide planning activities to assist with the identification and resolution of service quality gaps. Alternatively, they can be used in tracking root causes of problems with the service itself. Figure 2.3 shows a graphical representation of these dependencies and the distribution of their measurement in both situations.
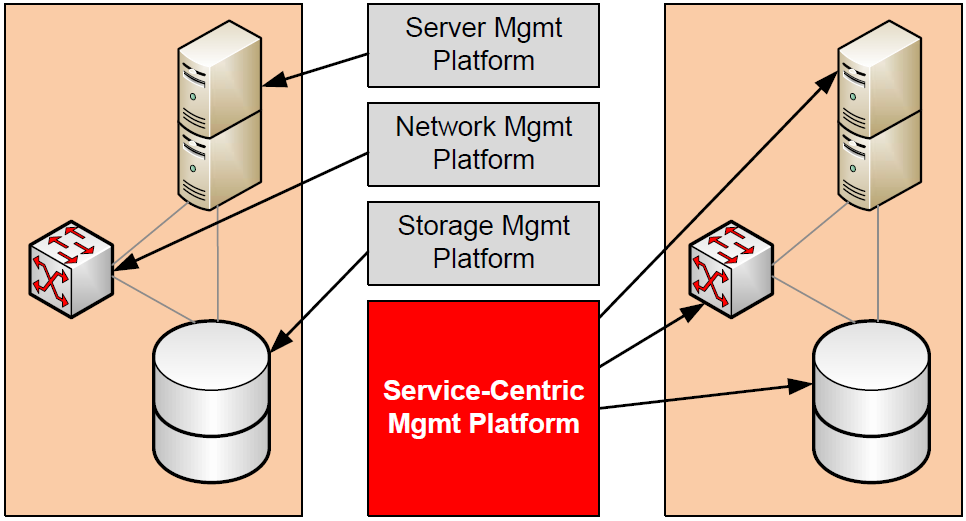
Figure 2.3: Segregated management platforms collect segregated quality metrics, while the service-centric approach can aggregate quality metrics across subsystems.
Improvements to Workflow
When considering the merge of virtualization and the service-centric approach to management, the enterprise environment stands to gain a number of direct benefits to its daily workflow. Some of these benefits arrive as a function of virtualization itself, while others are recognized when the automation enhancements associated with virtualization are considered.
Change Control
The change management activity is involved with ensuring the tracking and internal approval of changes prior to their implementation. It is also concerned with the assurance that those changes are logged into the organization's CMDB as necessary. Change control activities can be difficult to perform in the distributed environment due to the sheer number of interfaces required to be brought under management. The logging of individual changes is difficult when the number of interfaces is large, making the governance of change control a difficult practice as the environment scales.
The addition of virtualization to an enterprise environment brings an added level of change control to that environment as a function of the virtualization platform itself. Essentially, all mature virtualization platforms include change logging functions associated with the activities being done to virtual workloads themselves. Mature virtual platforms include the native ability to track when virtual machine actions are taken, such as powering on or off, snapshotting, console access, and others. The individual responsible for taking the action as well as when the action was taken are additional data that is typically logged by the virtualization manager.
This feature is unique and does not natively exist in the all-physical environment due to the fact that physical servers do not have a common layer of abstraction that they lie upon. Virtualization gains this capability for activity logging because all virtual machines must be operated through that layer of abstraction. Thus, every activity can be logged as it passes through that layer of abstraction.
This added logging ability is a boon to security as well as the auditing requirements needed to fulfill compliance regulations.
This capability is useful when all virtual workloads are hosted atop the same platform. But when multiple platforms are used, this change control data cannot be cross-examined between platforms. Leveraging non-platform-specific management such as the service-centric approach noted earlier, integration components can gather this change control data and pass it to centralized CMDBs as necessary to fulfill the control needs of the environment.
Configuration Control
Although virtualization itself does little to control the individual settings within a virtual machine, virtualization's ability to template servers makes the template a useful configuration item. Just like a physical server, each virtual machine and/or template will have a specific hardware configuration assigned based on its requirements. However, unlike physical servers where hardware configurations are based on a physical description of its characteristics, virtual machine hardware configurations are encapsulated into file-based data that is stored within the virtualization platform.
Digging even deeper, there are unique characteristics that exist between virtual machines that are of the same template, providing markers that can be used to identify a sort of "genealogy" among virtual machines. For example, virtual machine B was based on virtual machine template A, and so on. This identification assists configuration control managers with maintaining an accurate picture of configurations across the environment.
Leveraging automation components both native to virtualization platforms as well as those using the service-centric approach, these configuration items can be gathered and stored within CMDBs as necessary and appropriate for the environment. This action automates an often otherwise manual activity, reducing the overhead costs to the environment.
Release Management and the Deployment Process
Continuing with the story associated with templates, both release management and the deployment processes stand to gain through virtualization as well. Automation components exposed through individual virtualization platforms and aggregated at the service-centric management platform layer eliminate the highly manual steps of taking a physical server from request to resolution. Effectively, the virtualized organization can go from request to completion in minutes rather than weeks.
To illustrate the power of this capability, the first column of Table 2.1 provides common steps for a physical server build and deployment. The right column shows how the process improves when using virtualization's rapid deployment capabilities.
| Physical Server Deployment Steps | Virtual Server Deployment Steps |
| Identify need and log request | Identify need and log request |
| Ascertain physical inventory | Identify needed hardware characteristics |
| Identify needed hardware characteristics | Virtually provision server from OS template |
| Specify hardware configuration to vendor | Notify requestor of completed activity |
| Obtain purchase authority | |
| Purchase server | |
| Receive server | |
| Identify physical location for server storage, including power, cooling, networking, and other needed physical characteristics | |
| Physically provision server | |
| Install OS to specifications | |
| Install needed applications | |
| Notify requestor of completed activity |
Table 2.1: The time-to-completion for a server deployment is greatly enhanced through the use of virtual servers.
In this table, it is easy to see how the process from requesting a new server or service to its ultimate deployment is shortened by hours or days—or even weeks in the case of a vendor purchase. This increased level of agility enables IT to spin up new servers and services quickly to meet the demands of the business. Virtualization's hardware requirements mandate that IT keep adequate spare capacity on hand to support new server or service requests as necessary. Yet the purchase planning associated with these needs can be performed at a much more measured pace, based on aggregate demand rather than unit-by-unit requests as required by projects in their phases of completion.
License Management
Depending on the OS chosen, there are special benefits to licensing once workloads are virtualized. For example, certain editions of the Microsoft Windows OS enjoy added virtual licenses for each physical license purchased. Some applications may enjoy lower cost of ownership based on the impact of virtualization on their licensing terms. Conversely, a rare few applications actually cost more to virtualize upon analysis of the legal terms stated in their End User Licensing Agreement. Understanding the impacts of licensing and its relation on the budget is an important facet of any decision to move to virtualization.
One downside of virtualization's automation flexibility lies within the capability to rapidly create new servers. When it is easy to create new servers, service design teams may not pay careful attention to service needs in favor of simply adding new—and unnecessary—servers. This propensity to scale out rather than scale up can result in a significant negative impact on license cost over time.
Individual licenses can be difficult to track when using the platform tools provided by virtualization vendors. These tools are designed to focus on the individual workload as the management item and not its internal composition. But virtual machines when hosted must be done so with an identified OS. This information when combined with the internal systems management data that can be gathered through a service-centric approach can automate much of the license management process. This automation comes only as part of the integration of these two parts.
Notwithstanding how license information is gathered and monitored, smart organizations who virtualize must lay in place a program of governance to ensure that virtual bloat does not impact the organization's expected budget. One way that governance can be done within the virtual platform tools is with the introduction of quotas. Quotas in the virtual platform sense are a hardcoded limit of simultaneously hosted virtual machines that can be created by an identified individual or group. Attempts to build virtual machines beyond these limits are prevented through the interface. Integrating this information with physical data gathered through a servicecentric management solution allows for holistic governance of the total count of systems under management.
This point cannot be stressed enough. Lacking effective governance, your count of virtual machines will expand to fill available resources. Enabling and monitoring quotas is critical to ensuring that a down-the-road true-up of servers to licenses is not a significant negative impact to your budget.
Strengths of Service-Centric Management Platforms
To this point, this chapter has attempted to illuminate the framework in which the service-centric approach provides benefit to the IT environment. But the discussion is not complete without a high-level look at the software solutions that enable its functionality. The architecture of servicecentric management platforms are in and of themselves software-based solutions that can include any or all of the following components, which are shown in graphical form in Figure 2.4:
- Data gathering integrations. Information gleaned from elements in the IT system is gathered through the use of integration components. These integration components can be agent-based or agentless solutions that watch for preconfigured metrics on identified systems.
- Administration integrations. In addition to data gathering capabilities used for the processing of metrics, the service-centric architecture includes integrations that interface with IT elements for the purposes of administration. This enables the system to take action when situations occur as well as provides a location for administrator interaction with managed systems. These administration integrations can plug into virtualization solutions, individual servers, as well as networking, security, and storage subsystems.
- Framework and workflow integrations. Process frameworks such as ITIL v3 include best practices for accomplishing necessary actions within the IT environment. A servicecentric architecture will include the necessary framework integrations to ease the process of setting up workflow for environment activities.
- Visualizations. Information and actions must be displayed to administrators in a way that relates to their needs. A service-centric architecture will include the ability to create multiple visualizations based on metrics data and administrative needs for reporting and administration of the environment.
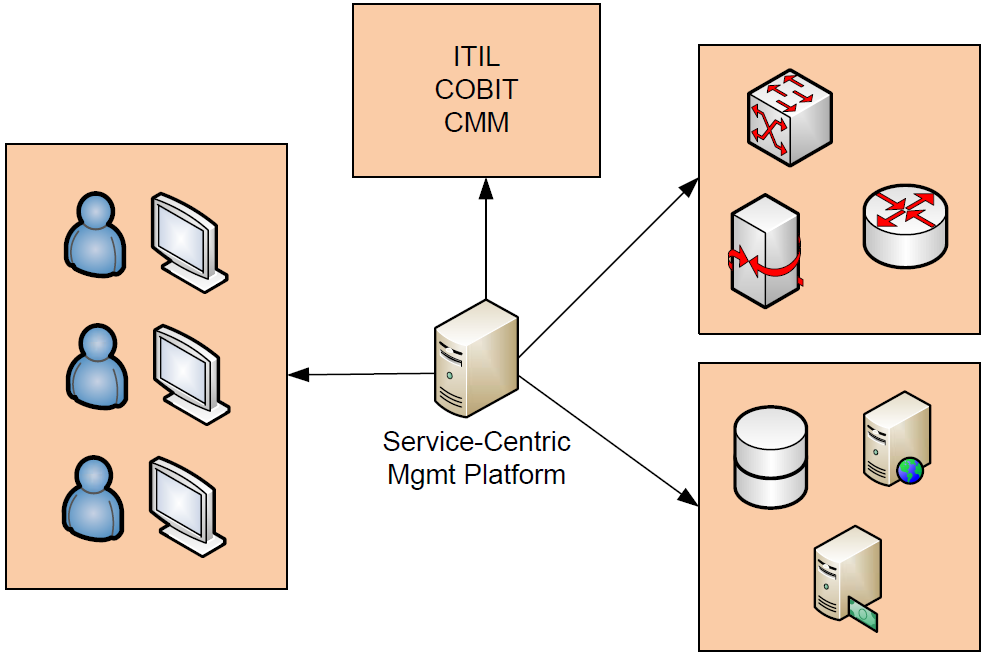
Figure 2.4: As a software solution, service-centric management platforms will include data gathering and administration integrations, framework and workflow integrations, and customizable visualizations based on user need.
Multiple software solutions exist that relate to the architecture discussed here, and the needs for your environment will vary. Thus, when considering a software solution that fulfills your virtual and physical requirements, consider the few key strengths in the following sections as important for a best-in-class solution.
Virtualization Vendor Agnostic
Multiple virtualization vendors exist, as do multiple virtualization architectures. One virtualization vendor or architecture may better support the needs of your specific workloads over another. Thus, widespread support for vendors and their architectures is critical in identifying a best fit.
Yet what is equally important is the capability for your desired virtualization solution to include the necessary application programming interfaces (APIs) to allow service-centric integrations to work. These APIs work at the virtualization management layer to expose necessary functionality to be used by service-centric integration components. Most enterprise-class virtualization solutions include the necessary components; however, supportability across the potential swath of virtualization platforms should be a key concern prior to making a purchase decision.
It is important also to recognize that enterprise virtualization comes in many forms: hardware virtualization, desktop virtualization, application virtualization, and others. It may be desirable by an organization to look for compatibility not only for the types of virtualization used in the data center itself but also those elsewhere in the environment.
As examples, desktop virtualization solutions enable virtualization at a user's desktop without needing to access infrastructure within the data center. Application virtualization provides a mechanism for abstracting applications themselves to desktops. Integration with other virtualization architecture found in the storage and network subsystems may also be desired. A full-featured service-centric management solution will include the necessary integration components to work with each of these solution classes.
Physical Vendor Agnostic
All virtualization solutions require some level of resources in the physical world as well. Even virtual machines require a physical server to processes their workload throughout their life cycle. For this reason, the solution chosen to support your virtualization needs must also include the widespread integration capability with all the physical assets in your environment.
These assets can relate to the server equipment upon which your business workloads—both physical and virtual—are hosted, the networking equipment that connects them, and the storage and security subsystems that house data and protect the environment. It also means support for the OSs and appliance devices that may be currently in use within the environment.
A best-in-class service-centric management solution will include integration components that not only work with OS components but also with enterprise-class hardware interfaces. As with the API exposure in the virtual world, this capability requires support by both halves of the solution. Your service-centric management solution must include the integration support to work with your needed hardware and OSs, while those OSs and hardware platforms must be capable of being managed through external interfaces.
For this reason, the use of "white box" servers or low-end networking equipment, for example, is not considered a best practice for the enterprise. Although these solutions tend to be of lower cost, they don't often include the necessary support for external management platform integration.
Uniform Management Across Servers, Networks, Storage, and Clients
Multiple universally accepted protocols exist today for the management of IT elements such as servers, networks, storage, and clients. SNMP and Web services-based management protocols are but two of those available today that work across entire classes of devices. But those universally accepted protocols are only one portion of the ecosystem. Some vendors include their own proprietary public interfaces for integrating with their platforms. Your service-centric management solution must include the support to work with the entire set of elements that make up your IT infrastructure.
At the same time, the management functionality that is eventually exposed to the administrator must be uniform as well. IT administrators are likely familiar with working with the vendorsupplied management utilities that arrive with individual products. Your service-centric management solution must include the same level of support or greater for needed administrative functions if your IT organization is to use the platform. In addition, the functionality provided by your service-centric management platform must arrive in a way that is easily accessible, easily useable, and easily trainable to IT personnel.
Chapters 3 and 4 will talk in more detail about the scripted actions commonly desired by IT administrators; consider the following list as necessary capabilities that are required to properly support the IT environment:
- Event and performance data visualizations. The ability to collate cross-device event and performance data is a key value to a service-centric management system. This enables troubleshooting teams to identify and track issues and problems. It further allows planning teams to look for areas in which service quality is not being met. Business services in enterprise environments are often comprised of multiple IT elements, so cross-device support provides a unified place that visually represents the behaviors across all elements that make up a business service.
- Monitoring and alerting. The data that arrives through element integrations tends to be large in quantity. Thus, actioning on it in real time requires monitors and alerts to be set for the notification of administrators. Cross-device monitoring enables the IT organization to quickly identify and resolve conditions that have gone beyond acceptable norms.
- Scripted actions and auto-remediation. Adding actions to monitoring data is another key feature when behaviors can be strongly isolated. Auto-remediative actions enable the IT environment to self-correct as situations occur. Scripted actions provide a way for administrators to rapidly deploy structured changes as necessary across the environment.
- Root cause analysis. Primary above all these is the need to distill through raw event and performance data to quickly identify what data is useful to identifying problems. This capability for root cause analysis is a key differentiator between service-centric management solutions and those of a lesser scope. Because a service-centric management solution has vision into essentially every layer of the IT environment, the information it gathers can automatically be used for a deeper analysis of problems to quickly direct troubleshooting teams to a resolution.
- Issue and problem prioritization. Lastly, business prioritization of problems and issues is another differentiator that assists large-scale IT organizations with applying human resources to the highest priority problems first. Integration with process frameworks and workflow enables service-centric management solutions to point the right teams to problems while reserving lower-priority solutions for later resolution.
Cross-Silo Coordination
By training and by experience, IT naturally tends to see a siloing effect with its workers. Those that focus on the network tend to avoid server systems. Those who primarily work within virtualization may not have high levels of experience with storage. Desktop and server teams rarely cross over. This siloing of individuals also incurs a cost to the organization in terms of intercommunication. A server application problem that has a network basis can be more difficult to track down because the application teams and the network teams speak different languages and have different mechanisms for problem identification.
The major reason for this siloing effect has to do with the complicated nature of IT itself. An individual who has a large amount of experience in networking accumulates that experience at the cost of other silos. Because of this, external solutions such as those gained through servicecentric management solutions enable all teams to work within a common interface and a common language.
Virtualization's impact on the IT environment actually exacerbates this problem of intercommunication. Virtualization has a tendency to increase the density of services, bringing together a greater count of services onto fewer numbers of equipment. This increased density means that all the typical IT players must work closer together in the maintenance of the virtualized environment.
As a real-world example, 10 virtual servers hosted atop one virtual host brings together 10 network connections, 10 storage dependencies, 10 different application sets, and the performance management associated with each. This enhanced density can result in lower service quality if not properly monitored by each team; an activity that you can see requires more attention than was necessary prior to virtualization.
The service-centric approach and the solutions that enable it bring a common language and interface to the workings of IT. With a service-centric management system, networking, server, application, and storage personnel all gain insight into the same console for metrics visualization and administration. Each gains the visibility previously only available to the others, allowing each previously siloed participant to see the entire picture and work towards the common goal of maximizing service quality.
The Run Book Automation Approach
One way in which the previously mentioned elimination of IT silos works is through the use of Run Book Automation (RBA) functionality. The concept of RBA encapsulates the ability to orchestrate actions across the IT system irrespective of the element involved. An RBA approach leverages the administration interfaces gained through incorporation of a service-centric management solution to create automation workflows for the resolution of known issues.
In terms of virtualization, an RBA approach can enable the networking, storage, processing, and other elements of virtual workloads to be centrally coordinated. This speeds the completion of known activities, such as creating new workloads or augmenting others as necessary. Your service-centric management solution should integrate with known IT process frameworks and include rich editing capabilities for creating workflows across IT devices as necessary.
As an example, a Run Book orchestration may enable through a few clicks:
- The creation of a new virtual machine and installation of its primary OS
- The provisioning of its needed networking and storage
- The identification of its primary host and high-availability configuration
- The installation of necessary prerequisite applications
- The configuration of access control to enable the right access to the right personnel
- The encapsulation of the results of this process into the organization's CMDB for asset tracking
Cautions with Service-Centric Management Platforms
Admittedly, there are a lot of lofty goals identified in the previous section. At first blush, a service-centric management solution appears as if it could automatically solve all the needs of the IT environment. Although you should never trust the vendor offering a panacea, with the right configuration, such a solution goes far in achieving value-based utility IT. In getting to that state, there are a few cautions that must be considered for organizations moving down the road of proactive holistic management.
Spin-Up Cost
Being comprehensive solutions, service-centric management platforms can involve a large spinup cost. This cost is incurred not necessarily from the initial cost to get the software in-house but to properly customize it for your environment. Service-centric management solutions by nature tend to arrive on-site as "empty containers" awaiting configuration for the target environment. To be most successful, this configuration requires a formal deployment process that identifies and brings IT assets under management. This process can take an extended period of time, and can be the largest cost associated with the move to a service-centric management solution.
Learning Curve
Although individual visualizations enabled for administrators and users should be designed to be easy to use, the sheer magnitude of a service-centric management solution requires a development team with cross-functional experience. Similar to the situation noted earlier in which networking teams tend to silo into networking experience, the teams used to bring a service-centric management solution online must be comprised of those with the necessary experience to integrate IT elements. Assurance that the right skills are in place is critical to achieving success with a service-centric management solution deployment.
Scope Creep
The same all-encompassing magnitude that makes service-centric management solutions attractive to enterprise businesses can also be its downfall if the scope of the project is not managed. With the potential for these solutions to touch so many parts of the IT environment, the desire to add those integrations can turn a deployment into a never-ending rollout. Proper project management and requirements generation prior to a deployment are critical to keeping the scope inline and achieving success.
Service-Centric Tools and Service Life Cycle Management
The last element to be discussed in relation to the service-centric approach is in relation to its integrations with process frameworks such as ITIL. The workflows associated with process frameworks provide an established mechanism for the resolution of problems and issues as well as the proper adjudication of behaviors as seen through even data. Effective solutions will include the capability to create workflows that enhance an organization's event, incident, and problem management processes.
Event Management Process
Event management in the non-optimized organization is highly device-centric. Individual devices typically log information about their behaviors only to themselves, making difficult the process of cross-device behavior determination. An effective service-centric management solution will include the following event management capabilities:
- Rich maintenance of event monitoring rules. The solution chosen should have the capability of determining events of interest and completing actions based on those events.
- Event creation, filtering, and dissemination. Once created by the offending IT system, events should be filtered for relevance and disseminated to the correct personnel for resolution.
- Event correlation and response. Leveraging the system as well as other tools, responders should be able to view the event in relation to others as well as other ongoing behaviors to determine an appropriate response.
- Event review and closure. Once completed, some capability for resolution and tracking of the event should be available to improve the response for the next incident.
Problem Management Process
Problems that occur within the IT system must also have predetermined workflows ready for use. Those workflows enable the quick resolution of problems before they turn into incidents that can impact environment functionality. An effective service-centric management solution will include problem management processes that support:
- Proactive problem monitoring. The integrations enabled through a service-centric architecture will provide a starting point for the identification of negative behaviors within the service. When negative or non-nominal behaviors occur, those situations should be monitored by the solution and administrator notifications given as necessary.
- Problem identification and categorization. Once a problem has been identified, that problem should be given a categorization and prioritization by the system. This data assists troubleshooting teams with identifying the domain for the problem and the level of effort to be assigned.
- Problem diagnosis and root cause analysis. As discussed earlier, with enough monitoring data in place across enough IT elements, it is possible for the system to gain a holistic situational awareness of the environment. This enables root causes for identified problems to be located across all the elements that make up the IT environment.
- Problem resolution and closure. Once identified, the system should provide exposure for resolving the problem either through a configuration change or a re-architecting of the service. Upon completion, the closure process should allow for the review of problems as necessary for improvement activities.
Incident Management Process
The proper management of incidents is critical to ensure resources are quickly brought to bear and a speedy resolution is achieved. Doing this with business services that span multiple IT elements requires coordination between teams and the availability of actionable information. The assist from your service-centric management solution can come in the following ways:
- Incident identification and categorization. The ability to declare an incident and bring the right triage resources to bear is critical to prevent a small situation from turning into a large one. Properly identifying and categorizing the event is key to accomplishing this task.
- 1st/2nd level support including escalation. Once identified, 1st and 2nd level support resources must be tasked with resolution as necessary. An effective solution will include the ability to identify resources as necessary and enact escalation procedures per predefined workflows.
- Coordination including user coordination. Especially in the case of major events, coordination among support teams and notifications to users are critical. Large events often affect multiple locations within the business service, requiring the support of multiple teams to resolve the situation. When events occur that involve user impact, ensuring users can be proactively notified is equally critical.
- Incident resolution and closure. As with each of the other two processes here, once the incident is resolved, closure procedures that enable future review are useful for later analysis.
Throughout all these processes, a comprehensive reporting mechanism for all events, problems, and incidents is critical to drive downstream improvement activities.
The Service-Centric Approach Has Far-Reaching Impacts on Operations
The automation benefits associated with virtualization are augmented through the incorporation of extra-platform solutions. These solutions enable virtualization to work in tandem with other IT administration needs rather than in parallel with them. An investment in the service-centric approach has the potential to pay dividends in terms of unifying monitoring and management functionality under a single banner, bringing the automation of virtualization inline with other elements of the IT infrastructure.
In Chapters 3 and 4 of this series, we will descend from the 20,000-foot perspective towards a more functional analysis of virtualization's automation potential. Chapter 3 looks at the impacts to change management, while Chapter 4 looks at problem resolution, both of which gain useful benefits when framed through virtualization's automation potential.